Federated Learning Framework & ECSTA Simulation Testbed
- Project
- 21017 EARS
- Type
- New product
- Description
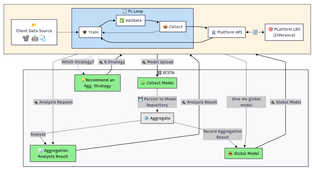
A production-oriented Federated Learning (FL) framework paired with the ECSTA simulation testbed to design, validate, and operate privacy-preserving recommender systems across multiple partners. It provides secure parameter sharing, synchronization and aggregation policies, full model lifecycle management (versioning, rollback, audit), and governance. The framework exposes interoperability-ready APIs and schemas, supports cloud/on-prem/edge deployments, and integrates explainability (human-readable rationales) by design.
- Contact
- Arda ÖDEMİŞ (ARD Group)
- project.team@ardgrup.com.tr
- Research area(s)
- Federated Learning, Privacy-Preserving ML, Recommender Systems, Explainable AI, Interoperability & Standards (APIs, data schemas, semantic alignment)
- Technical features
This provides a production-ready federated training core supporting synchronous/asynchronous rounds (e.g., FedAvg with pluggable reducers), straggler tolerance, partial participation, and secure client bootstrapping via Python/REST SDKs with checkpoint resume. Privacy and security are built in with transport encryption, optional secure aggregation, per-field masking, RBAC with token-based authentication, signed artifacts, and end-to-end audit trails for lineage and provenance. A full MLOps layer manages model versions and metadata with policy-based promotion/rollback and automated evaluation gates for metrics, bias, and drift before global release, while continuous training hooks enable scheduled federated rounds. Interoperability is ensured through stable REST/JSON APIs, reusable schemas for models/metrics/events, webhooks and message-bus adapters, plus import/export in common formats (e.g., ONNX, PyTorch). Explainability is first-class: pluggable XAI providers generate human-readable “why” payloads alongside recommendations. Operations are supported with real-time dashboards, structured logs, traces, alerts, multi-tenant isolation, and quota controls, and deployment is portable across cloud, on-prem, and edge with containerized services and horizontal scaling. The ECSTA simulation testbed adds synthetic data generators, scenario scripts, and fault injection (dropout, drift, poisoning) to A/B aggregation policies in batch or real time, benchmarking throughput, latency, and convergence. Finally, configurable data governance features cover retention, pseudonymization hooks, consent and processing records, and exportable audit packs for external assessments.
- Integration constraints
Integration follows the project’s interoperability framework: services expose versioned REST/JSON contracts validated against OpenAPI at an API Gateway that terminates TLS, enforces OAuth-based identity federation, rate limits, and emits access logs; asynchronous flows use a broker (e.g., AMQP/RabbitMQ) with persistence, retries, and dead-letter queues for resilience . All external APIs must run over HTTPS with TLS 1.3 or higher; inter-service calls support mutual TLS, signed updates, and replay protection; access is governed by OAuth2/OIDC with RBAC claims embedded in JWTs and enforced per endpoint and operation . Federated integration requires exchanging model parameters/gradients (never raw data), scheduled push of updates to aggregation services, and secure aggregation (e.g., SMPC/HE) with optional differential privacy; identifiers used in shared artefacts/logs must be pseudonymized/tokenized and privacy controls configured per jurisdiction (GDPR/KVKK) . Backward/forward compatibility is managed via semantic versioning across resources, schemas, topics, and gateway policies; tolerant validators ignore unknown fields, and older clients remain supported through explicit URL versioning and parallel topic streams . Integration quality gates require contract checks in CI, staged functional tests against agreed SLOs, and resilience/security scans (e.g., broker outage, OWASP ZAP/Trivy) before promotion . At the platform level, components interact through a unified gateway and security layer (AAA/RBAC) while managing recommendation models and logs; this enforces secure API-mediated communication across domains and supports microservice scaling via containers/Kubernetes to meet performance targets (e.g., sub-1.5s API responses under load) with optional adapters for legacy SOAP/XML/CSV systems . Finally, error handling must use standard HTTP codes with structured JSON bodies, and centralized logging/monitoring is required for troubleshooting and auditability across tenants and roles
- Targeted customer(s)
Primary customers are data-sensitive enterprises and public agencies that need privacy-preserving recommendations and analytics across distributed data silos—e.g., hospitals and healthcare networks, financial institutions, telecoms, media/OTT, and large e-commerce/retail marketplaces. Typical buyers include Heads of Data/AI, CIO/CTO offices, and platform teams operating multi-tenant or multi-site systems. Secondary customers are ISVs and OEMs seeking to embed federated learning and explainability into their products.
- Conditions for reuse
This is available under a commercial Enterprise License with an Evaluation License for pilots; client SDKs may include permissively licensed open-source components with required notices. Reuse requires acceptance of the API/SDK EULA, adherence to privacy/security controls (TLS, OAuth2/OIDC, RBAC, audit logs), and for federated setups a DPA/Participation Agreement ensuring only parameters/gradients—not raw data—are exchanged. Redistribution is restricted (OEM addendum required), IP stays with each party’s pre-existing assets, support is provided via a separate SLA, and export/branding uses require compliance and prior approval.
- Confidentiality
- Public
- Publication date
- 12-11-2025
- Involved partners
- ARD GROUP (TUR)
Images