Smaller models, comparable results, reduced costs: learnings from the GENIUS project
Within the GENIUS project, that aims to make generative AI usable across all phases of the software development life cycle, collaboration has played an important role in developing smarter and more cost-efficient AI solutions. One project working group in particular has been actively sharing knowledge, research findings, and industry insights on information retrieval. An interesting example of this collaboration involved Austrian project partners CASABLANCA hotelsoftware, the University of Innsbruck, and c.c.com Moser GmbH.
Together, they explored how Retrieval Augmented Generation (RAG) can deliver high-quality results without relying on the largest and most expensive language models. As cutting-edge AI models from providers like OpenAI, Microsoft, Google, and Anthropic continue to grow in size and capability, their operational costs rise accordingly. This led within GENIUS to a practical question: Do real-world applications always require the biggest models to achieve strong performance?
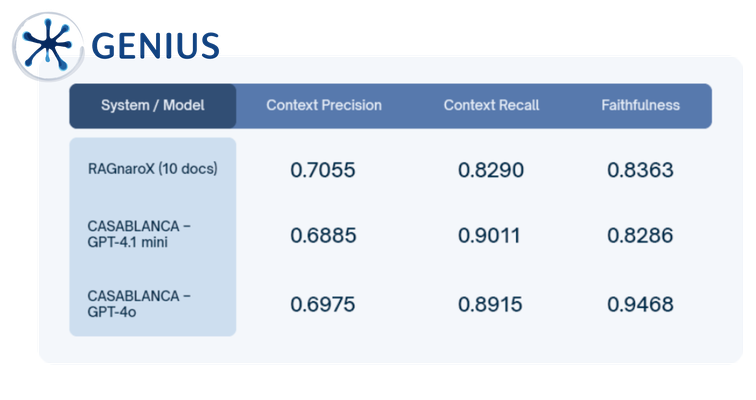
To investigate this, the partners conducted a joint RAG experiment using CASABLANCA’s documentation. They compared frontier models such as GPT 4o with smaller alternatives like GPT 4.1 mini, as well as RAGnaroX, a local prototype developed by c.c.com Moser GmbH. The results were clear: smaller models delivered nearly identical accuracy when retrieving factual information from structured documents.
Beyond the cost savings of around 75%, smaller models offered additional advantages: lower latency, increased flexibility, faster response times, and easier customisation for domain-specific content. These benefits are especially valuable in RAG systems, where responses must be tightly grounded in retrieved documents.